From RAG to Context - A 2025 Year-End Review of RAG
https://ragflow.io/blog. On the ragflow website appears frequently a very insightful blog!
As 2025 draws to a close, the field of Retrieval-Augmented Generation (RAG) has undergone profound reflection, vigorous debate, and marked evolution. Far from fading into obsolescence as some bold predictions foresaw—amid lingering scepticism over its supposedly transient role—RAG has solidified its indispensability as a cornerstone of data infrastructure in the demanding arena of enterprise AI adoption.
Looking back, RAG’s trajectory this year has been complex. On one hand, its practical effectiveness faced significant skepticism, partly due to the “easy to use, hard to master” tuning challenges inherent to RAG systems. On the other hand, its share of public attention seemed to be overshadowed by the undisputed focus of 2025’s LLM applications: AI Agents.
However, an intriguing trend emerged. Despite the controversies and not being in the spotlight, enterprises genuinely committed to building core AI competencies—especially mid-to-large-sized organizations—deepened and systematized their investments in RAG. Rather than being marginalized, RAG has solidified its core role in enterprise AI architecture. Its position as critical infrastructure remains unshaken, forming the robust foundation for enterprise intelligence.
Therefore, we must first move beyond surface-level debates to examine the intrinsic vitality of RAG technology. Is it merely a transitional “band-aid” to patch LLM knowledge gaps, or is it an architecture capable of continuous evolution into a cornerstone for next-generation AI applications? To answer this, we must systematically review its technical improvements, architectural evolution, and new role in the age of Agents.
Can RAG Still Be Improved?
The Debate About Long Context and RAG
In 2025, the core of many RAG debates stems from a widely acknowledged contradiction: enterprises feel they “cannot live without RAG, yet remain unsatisfied.” RAG lowers the barrier to accessing private knowledge, but achieving stable and accurate results—especially for complex queries—often requires extensive, fine-tuned optimization, complicating total cost of ownership assessments.
Consequently, the theoretical question heatedly discussed in 2024—“Can Long Context replace RAG?”—rapidly entered practical testing in 2025. Some scenarios less sensitive to latency and cost, with relatively fixed query patterns (e.g., certain contract reviews, fixed-format report analysis), began experimenting with directly using long-context windows. They feed entire or large batches of relevant documents into the model at once, hoping to bypass potential information loss or noise from RAG retrieval and directly address inconsistent conversational quality.
However, research since 2024 offers a clearer picture of the technical comparison. Mechanically stuffing lengthy text into an LLM’s context window is essentially a “brute-force” strategy. It inevitably scatters the model’s attention, significantly degrading answer quality through the “Lost in the Middle” or “information flooding” effect. More importantly, this approach incurs high costs—computational overhead for processing long context grows non-linearly.
Thus, for enterprises, the practical question is not engaging in simplistic debates like “RAG is dead,” but returning to the core challenge: how to incorporate the most relevant and effective information into the model’s context processing system with the best cost-performance ratio. This is precisely the original design goal of RAG technology.
Improved long-context capabilities have not signaled RAG’s demise. Instead, they prompt deeper thinking about how the two can collaborate. For example, RAG systems can use long-context windows to hold more complete, semantically coherent retrieved chunks or to aggregate intermediate results for multi-step retrieval and reflection. This “retrieval-first, long-context containment” synergy is a key driver behind the emerging field of “Context Engineering.” It marks a shift from optimizing single “retrieval algorithms” to the systematic design of the end-to-end “retrieval-context assembly-model reasoning” pipeline.
Currently, paradigms for providing external knowledge to LLMs mainly fall into four categories:
Relying solely on LLM’s long-context capability.
Utilizing KV Cache.
Using simple search methods like Grep.
Employing a full RAG architecture.
Cost-wise, there is roughly a two-order-of-magnitude gap between option 1 and option 4. Option 2 (KV Cache based) remains at least an order of magnitude more expensive than full RAG, while facing serious limitations in scalability, real-time updates, and complex enterprise scenarios.
Option 3 (index-free / Grep-style) works in very narrow, highly structured domains (e.g. clean codebases or logs) but fails completely for the majority of enterprise unstructured/multi-modal data.
Optimizations for RAG Conversational Quality
A common source of inaccurate or unstable answers lies in a structural conflict within the traditional “chunk-embed-retrieve” pipeline: using a single-granularity, fixed-size text chunk to perform two inherently conflicting tasks:
Semantic matching (recall): Smaller chunks (100–256 tokens) → better precision
Context understanding (utilization): Larger chunks (1024+ tokens) → better coherence
This forces a difficult trade-off.
A fundamental improvement is to decouple the process into two stages:
Search (scanning/locating): Use small, precise units for high recall
Retrieve (reading/understanding): Dynamically assemble larger, coherent context
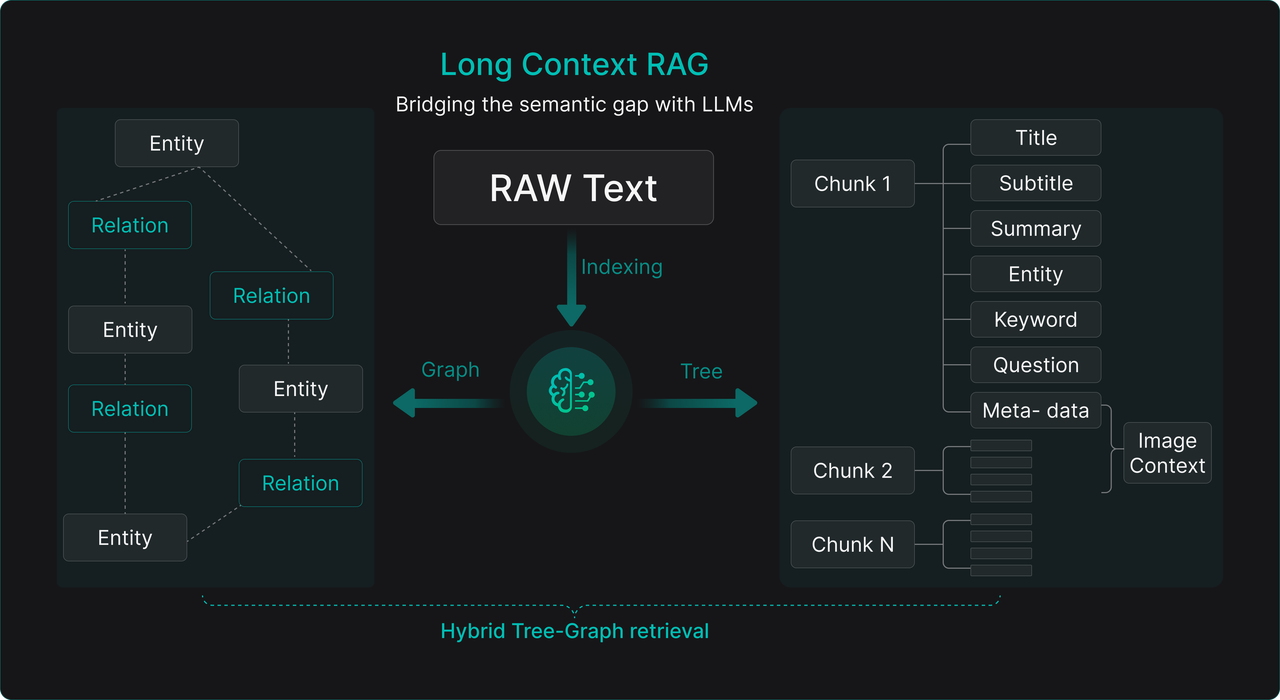
RAGFlow’s TreeRAG technology embodies this:
Offline: LLM builds hierarchical tree summaries (Chapter → Section → Subsection → Key Paragraph)
Online: Precise small-chunk search → use tree as navigation map → auto-expand to complete logical fragments
This mitigates “Lost in the Middle” and context fragmentation.
For even more complex queries (scattered info, cross-document reasoning) → GraphRAG (entity-relationship graphs) becomes relevant, though it has challenges:
Massive token consumption during graph building
Noisy auto-extracted entities/relations
Fragmented knowledge output
Hybrid TreeRAG + GraphRAG (“Long-Context RAG”) approaches appear most promising.
Modern RAG philosophy: Leverage LLMs during ingestion for deep semantic enhancement (summaries, entities, metadata, potential questions) → use this as intelligent “navigation map” during retrieval → achieve optimal balance of effectiveness, performance and cost.
From Knowledge Base to Data Foundation
RAG is an architectural paradigm, not just a Q&A tool.
With the rise of AI Agents, enterprise RAG is evolving into a general-purpose data foundation for unstructured data — serving as unified, efficient, secure access layer for all types of Agents.
A robust, scalable, configurable Ingestion Pipeline has become the core of modern RAG engines, handling the full lifecycle from raw documents to structured, semantically rich, query-ready knowledge.